


Lost in the Loop: The Fascinating Parallels Between Audio Feedback and AI Model Collapse
Lost in the Loop: The Fascinating Parallels Between Audio Feedback and AI Model Collapse
Exploring the Surprising Similarities in How Audio Feedback and Large Language Models Break Down


Welcome to this edition of The Process, a free weekly newsletter and companion podcast discussing the future of technology and philanthropic work.
If you enjoy reading and listening, please consider subscribing and sharing with your community!
Thank you!
Philip
Like smells, certain sounds can instantly transport us back to a particular moment in time. The sound of a dial up internet connection takes me back to the 1990s, to the days of AOL Instant Messenger and Napster. I wonder if another similar digital din from our present day will one day evoke similar nostalgia — Zoom meeting audio feedback.
You know the scene — two or more people log into the same video call, from the same room, without coordinating muting of microphones or speakers, and before anyone can react, everyone on the call begins to hear the eardrum-rippling atonal noise of an audio feedback loop. Eventually someone mutes something to stop the pain.
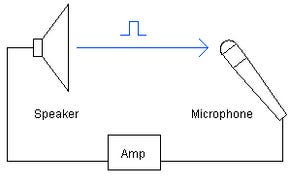
An audio feedback loop is caused when a sound is picked up by a microphone, travels through an amplification system, is outputted by a speaker, the sound of which goes immediately back into the microphone for another cycle. If we could slow this whole process down, what we would hear is the degradation of the original sound and signal, which loops through the system until it stabilizes at its own frequency, which is the unpleasant tone we’ve all heard before.
Model collapse
A study conducted in the UK appears to show a very similar phenomenon takes place when large language models (LLMs), like GPT, are trained using data created by artificial sources, as opposed to human-generated data. The researchers call this scenario Model Collapse, a condition in which the mathematical mapping of these massive models degrades, compromising its generative abilities.
We show that over time we start losing information about the true distribution, which first starts with tails disappearing, and over the generations learned behaviours start converging to a point estimate with very small variance.
The audio feedback analogy holds remarkably well throughout the diagram with sound representing LLM training data, the audio system is akin to the neural networks where deep reinforcement learning takes place, and finally the speaker corresponds to the numerous chatbots and AI content generators people are interacting with.
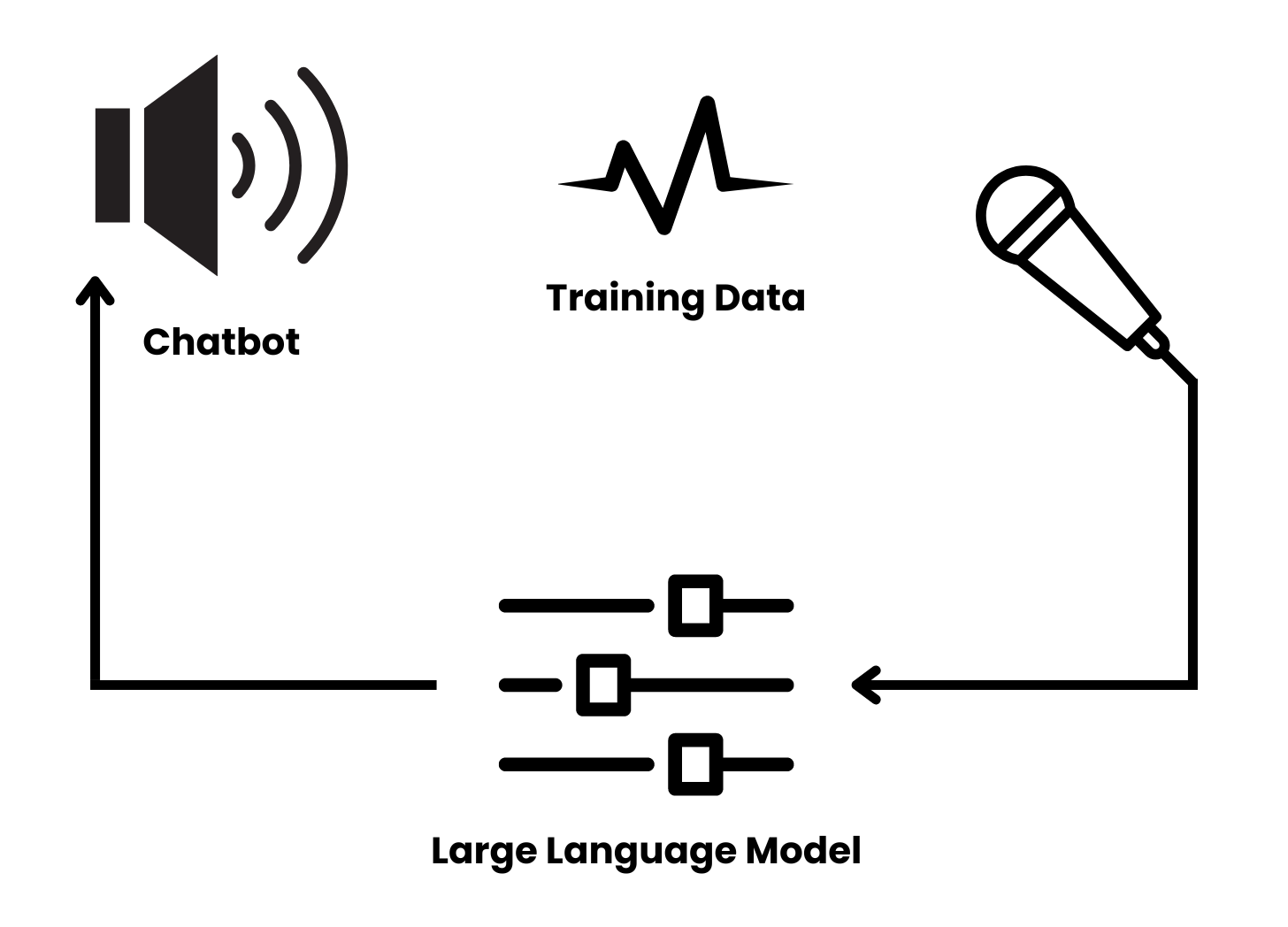
What the UK researchers have found is models trained using data generated by other AI models enter into a strikingly similar feedback loop, which, as in the case of audio, converges on a signal that has lost all of its expansive dimensionality. For audio, the richness and dynamics of a human voice, for example, collapses to become an earsplitting tone, while for LLMs, the vast data sets and the incomprehensibly complex statistical relationships the models learn during training, disintegrate to a “point estimate with very small variance”.
What is lost in the signal?
When sound waves, pulses of differential air pressure, contact the diaphragm of a microphone, the pulsations are translated into electrical signals, which are then reproduced by speakers operating in reverse by converting electrical signals back into sound. No matter how high-end your recording is system, there is loss of fidelity from the original sound. In feedback loops, the original sound comes out of the speaker a bit degraded from how it went into the mic, and when this happens hundreds of times in a second, the total amount of loss or degradation rapidly accumulates and the original sound becomes unrecognizable.
While it’s obvious sonic quality is what degrades in the audio example, what is being lost when AI models are trained on AI-generated data? What is the gap between human-generated and AI generated content? In a single instance, for example, a thank you note drafted by a person versus a note drafted by ChatGPT, there may not be any perceptible difference. But at quantities measured in exabytes (one billion gigabytes), which is the scale of large language model training data, these imperceptible disparities between human and AI-generated data add up to compromise a model’s viability entirely. Whatever the transcendent human element is, large language models cannot yet replicate it at scale.
All that precedes content
In order to mimic human creativity, it may be that models will need to train on more data from the creative process, itself, rather than the outputs of creativity, and it is unclear how this would be accomplished. This post you’re reading was the result of several hours worth of starts and stops, twists and turns, trial and error. I can’t even begin to fathom the sum of thoughts that have entered and exited my consciousness throughout the effort of writing this piece, leaving aside how all of it somehow coalesces into these words. Studying our content, AI models are still only able to consider the proverbial tip of the iceberg in the human creative process.
I feel uplifted holding these realizations. As I publish more content online, I understand I am, in essence, training my digital double — systems which are able to approximate my likeness across many information formats. And yet, for all the material my artificial understudy may ingest to learn “me”, it will not have the source material, my inner experience, from which my ideas and creativity flow. My double will lag, perhaps ever so slightly, behind the extent of what I am capable of.
What’s more, as the proliferation of AI-generated content accelerates across the internet, finding organic data, that is, data generated by people, for training new AI models, will become more challenging. The same practices scraping the internet may become unviable as the information ecosystem contains more and more artificial content, which if ingested by new models, could cause their collapse. This could mean organic content becomes more valuable, not less. I’m already thinking about ecological analogies I can flesh out in a future post!
The fate of future generative AI models, for now, seems linked with the flourishing of human inspiration. While it is a staggering feat of innovation and technology to decode the mathematical patterns of our collected digital works, peering into the vault of our inner experience, let along deciphering it, are challenges many orders of magnitude more difficult. All this to say, there are reasons to be optimistic about the prospects for creativity and creative work. For anyone who cares to share, I would love to hear your… well, feedback.
Thanks for reading this edition of The Process. Please share and comment or you can email me at philip.deng@grantable.co
Philip Deng is the CEO of Grantable, a company building AI-powered grant writing software to empower mission-driven organizations to access grant funding they deserve.